
Meet ALMA: A New Training Method That Boosts Translation Performance for Large Language Models
Researchers from Johns Hopkins and Microsoft propose a new 2-stage fine-tuning method that unlocks stronger translation abilities in smaller models with just 7-13 billion parameters.
Large language models like GPT-3 have demonstrated immense potential across an array of natural language processing tasks. However, for machine translation, smaller LLMs with just 7-13 billion parameters still lag far behind traditional encoder-decoder models by over 15 BLEU points. This is perplexing given that massive 175B parameter models like GPT-3 can rival state-of-the-art translation quality.
In a new paper, researchers from Johns Hopkins University and Microsoft propose a specialized training method that can unlock stronger translation capabilities in smaller LLMs, achieving performance on par with GPT-3.
Subscribe or follow me on Twitter for more content like this!
The Struggle of Smaller LLMs in Translation
In natural language processing, large language models have proven immensely effective across tasks like text generation, summarization, and question-answering. LLMs like GPT-3, PaLM, BLOOM, and OPT have shown the ability to perform zero-shot transfer learning, applying knowledge gained during pre-training to downstream tasks without additional fine-tuning.
However, for machine translation, smaller 7-13B parameter LLMs seriously underperform compared to traditional encoder-decoder models like NLLB. Even models in the same model family exhibit drastically different translation abilities based on size. For example, while the massive 175B parameter GPT-3 achieves high-quality translation rivaling NLLB, the 7B GPT-3 trails by over 30 BLEU points.
This performance gap persists across various modern LLMs. Models like XGLM-7B, OPT-7B, and BLOOM-7B fall 15-30 BLEU points behind SoTA models on benchmark datasets like WMT and Flores-101. So what explains this deficiency in translation for smaller LLMs?
Rethinking Translation Fine-Tuning for LLMs
The researchers hypothesize that smaller LLMs may not necessitate as much parallel text data during fine-tuning as historically used for training machine translation models.
Thus, simply fine-tuning LLMs on hundreds of millions of parallel sentences may not be the optimal approach. In fact, the authors find that excessive parallel data can actually dilute the pre-trained knowledge within LLMs and harm translation capability.
They propose a novel 2-stage fine-tuning recipe specifically tailored for unlocking the translation potential in LLMs:
Stage 1: Monolingual Fine-Tuning
- Fine-tune on monolingual data in non-English languages involved in translation.
- This strengthens comprehension in languages like Chinese, German, etc.
Stage 2: High-Quality Parallel Fine-Tuning
- Fine-tune on a small set of high-quality human-translated parallel text.
- This teaches the LLM to generate high-quality translations.
This approach does not require nearly as much parallel data as conventional methods. The researchers call LLMs fine-tuned this way ALMA (Advanced Language Model-based trAnslators).
Testing ALMA Models Against The State-of-the-Art
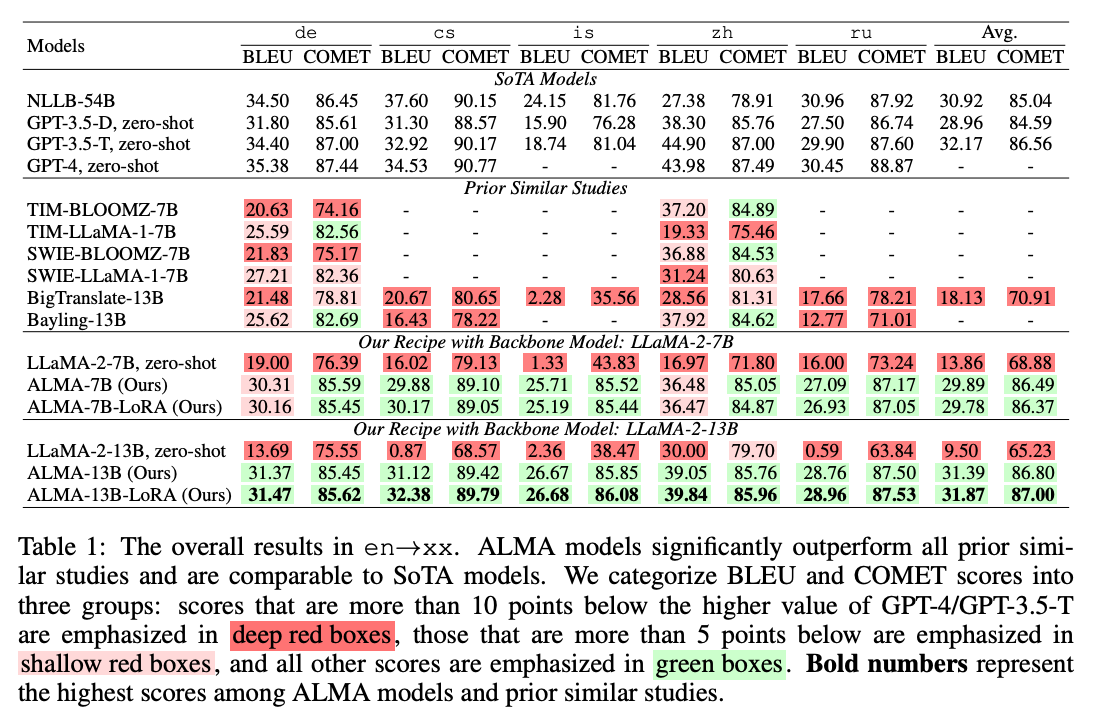
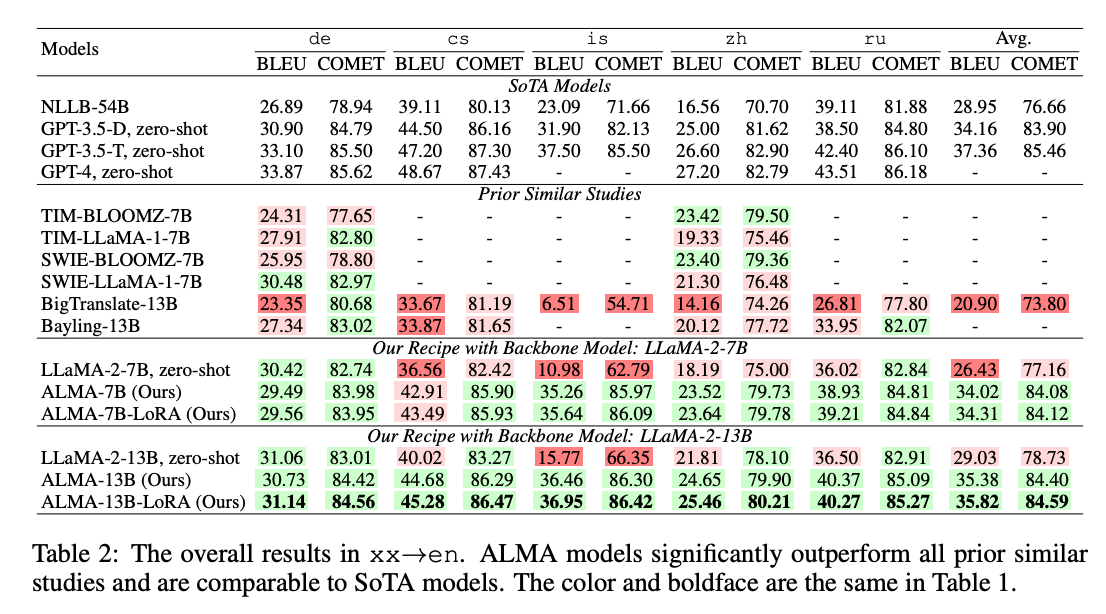
The researchers implemented ALMA models based on the LLaMA architecture with 7B and 13B parameters. They evaluated on 10 language pairs from WMT and Flores benchmark datasets including German, Czech, Chinese, Icelandic, and Russian.
The results exhibit the strengths of the proposed training recipe:
- ALMA substantially improves over LLaMA's zero-shot translation by over 12 BLEU and COMET.
- ALMA beats all prior work fine-tuning LLMs for translation by a large margin.
- ALMA slightly exceeds GPT-3 and NLLB despite having far fewer parameters.
- With just 1 billion monolingual tokens and 18 hours of training, ALMA reaches performance on par with the 54B parameter NLLB model.
Additional experiments reinforce the importance of monolingual and parallel data quality over quantity. The improvements shine through across high and low resource languages.
Redefining Translation for Large Language Models
This work puts forward a new training paradigm that eliminates the need for massive parallel text data that prevailing translation models are predicated on.
With compact, specialized fine-tuning, smaller LLMs can reach state-of-the-art translation quality without hundreds of billions of parameters. The study focuses on particular model architectures and languages, but points to the potential for tailored tuning approaches to unlock multilingual abilities in LLMs more universally.
Moving forward, we may need to reframe how we train LLMs for translation. The traditional wisdom of "more data is better" may not always hold. Rather than scaling up data, deliberate fine-tuning that targets key language capabilities could be the key to maximizing performance.
By revealing the potential for efficient yet powerful translation with smaller LLMs, this work lays the foundation for developing more accessible and scalable machine translation systems. This training recipe expands the possibilities for deploying capable multilingual LLMs in real-world applications.
Subscribe or follow me on Twitter for more content like this!


Comments ()