
All LLMs use tokenization. Are we doing it totally wrong?
Slashing model size by 85% while redefining how we build adaptable, efficient LLMs
What happens when you challenge one of the most basic assumptions in language AI? We’ve spent years making tokenizers bigger and more sophisticated, training them on more data, expanding their vocabularies. But what if that whole approach is fundamentally limiting us?
The researchers behind T-FREE, the top text generation paper on AIModels.fyi right now, ask exactly this. Their answer could change how we build language models. Instead of using a fixed vocabulary of tokens, they show how to map words directly into sparse patterns — and in doing so, cut model size by 85% while matching standard performance.
When I first read about their approach, I was skeptical. Language models have used tokenizers since their inception — it seemed like questioning whether cars need wheels. But as I dug into the paper, I found myself getting increasingly excited. The researchers are showing us how our standard solutions have trapped us in a particular way of thinking, and I think that’s a very refreshing way to look at LLM performance.
Consider what happens when a standard tokenizer encounters a word it doesn’t know. It frantically tries to break it into pieces it recognizes, like someone encountering a foreign word (or a giant technical one) and sounding it out syllable by syllable. This works, sort of, but it’s inefficient and error-prone. It’s also eerily similar to how early OCR systems worked — trying to match predetermined patterns rather than understanding the underlying structure.
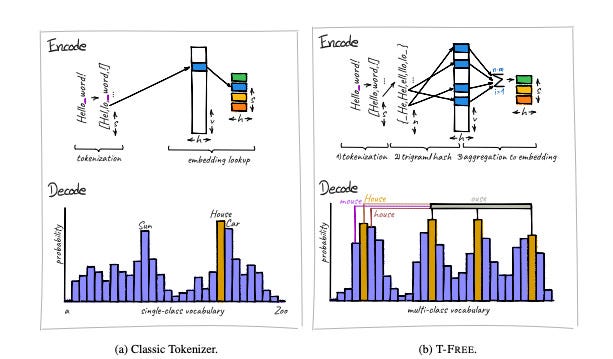
The researchers’ key insight is that we can exploit the natural patterns in how words are constructed. Instead of learning a fixed vocabulary, T-FREE maps words into sparse patterns based on their character sequences. This may sound abstract, but it’s actually closer to how humans process unfamiliar words. When you see a word you don’t know, you don’t consult a mental dictionary of subword pieces — you process its structure directly.
This shift from learned tokens to direct mapping is potentially a big deal. Current tokenizers are like tourists with a phrasebook — they can only say what they’ve been explicitly taught (funny how those phrases are so rarely useful!).
T-FREE is more like someone who understands the rules of language formation. It can handle new words gracefully because it understands patterns rather than memorizing pieces.

The technical implementation is clever but conceptually straightforward. For each word, T-FREE generates overlapping three-character sequences called trigrams. The word “hello” becomes “_he”, “hel”, “ell”, “llo”, and “lo_”. These trigrams then map to specific dimensions in the embedding space through a hashing function. Similar words naturally end up with overlapping patterns because they share trigrams.
This approach solves several problems that have plagued traditional tokenizers:
- The vocabulary bloat problem: Current models waste parameters on nearly identical tokens. “Word”, “word”, and “ word” each get their own embedding despite representing essentially the same thing. T-FREE handles these variations automatically through its trigram patterns.
- The language bias problem: Traditional tokenizers learn from training data, usually English text. This creates an inherent bias that makes them less effective for other languages. T-FREE works equally well across languages because it operates on character patterns rather than learned tokens.
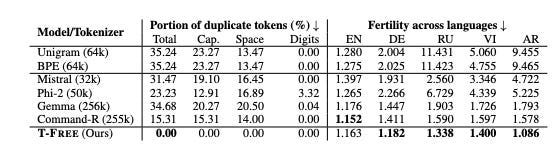
- The scaling problem: Recent models like Command-R use over 6 billion parameters just for embedding and output layers. T-FREE cuts this by 87.5% while maintaining performance. That’s not a typo — they’re getting the same results with less than one-eighth the parameters.
But perhaps most exciting is what this enables for the future. By breaking free from fixed vocabularies, T-FREE opens up a new tech tree branch for language models that can adapt more flexibly to different domains and languages.
The researchers validate their approach through extensive experiments, training models from scratch and comparing them against traditional architectures. The results are: comparable performance on standard benchmarks, better handling of multiple languages, and dramatically improved efficiency.

Not bad!
There are still open questions, of course. The approach might struggle with very long compound words or highly specialized technical vocabularies. Some of these challenges might be addressed through hybrid approaches that combine T-FREE’s pattern-based mapping with traditional tokens for special cases.
But I think focusing on these limitations misses the larger point. T-FREE is a demonstration that some of our field’s basic assumptions deserve questioning. It shows us that sometimes the best way forward isn’t to optimize our current approach, but actually to step back and ask whether there might be a fundamentally better way to do something we consider core to our way of working and therefore immune to change.
The researchers close their paper by suggesting future directions they’d take their investigations — combining T-FREE with traditional tokenizers, extending it to handle specialized notation, exploring applications beyond text. But again, the specific suggestions matter less than the broader lesson: sometimes the biggest breakthroughs come not from improving our current solutions, but from questioning whether we’re solving the right problem in the first place.
What do you think? Let me know in the comments or on Discord. I’d love to hear what you have to say.


Comments ()