
LLMs surpass humans in predicting which neuroscience experiments will succeed (81% vs 64%)
AI could help researchers prioritize promising experiments, accelerating discovery and reducing waste.
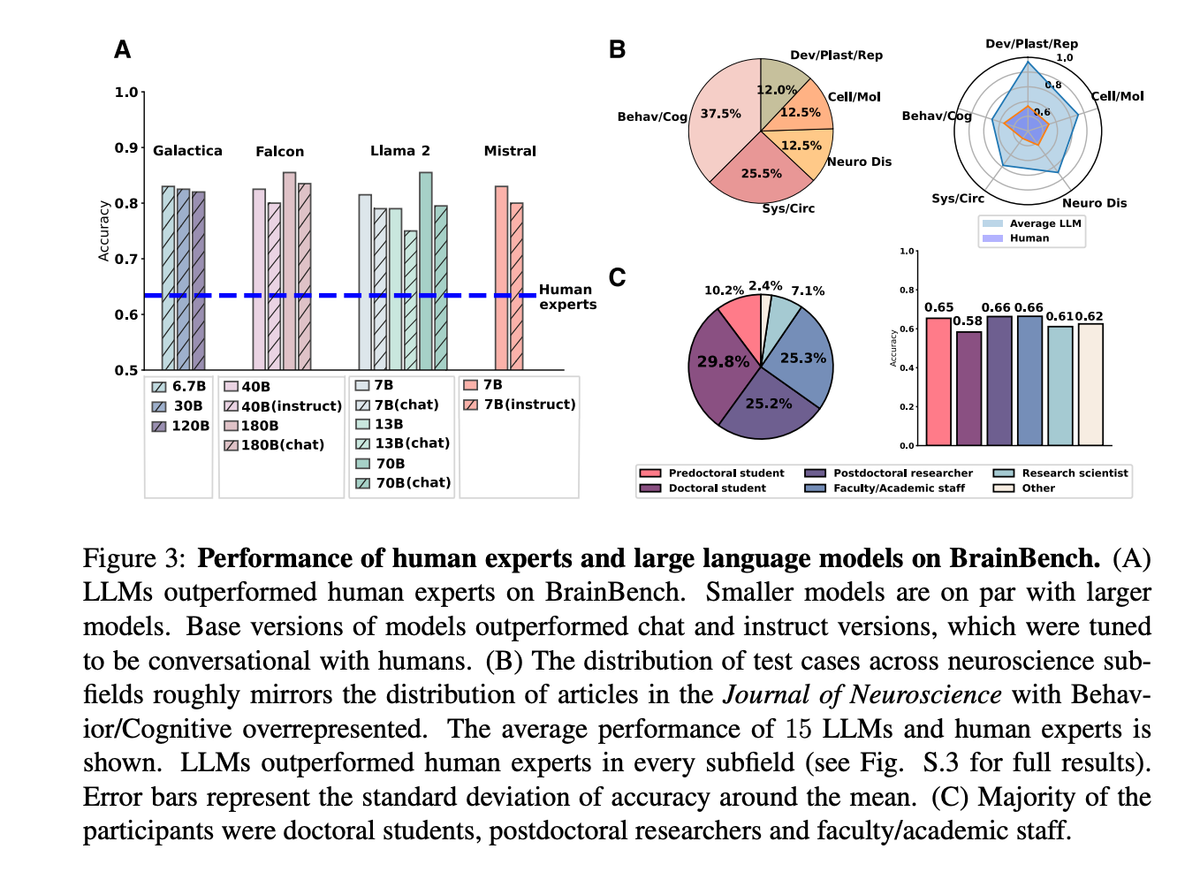
A new study by Xiaoliang Luo and colleagues has shown that large language models (LLMs) can predict which neuroscience experiments are likely to yield positive findings more accurately than human experts. Interestingly, the researchers used a mere GPT-3.5 class models with 7 billion parameters and found that fine-tuning these models on neuroscience literature further improved their performance.
In this article, I'll explain why this is such a big deal and how the researchers were able to build a system that not only out-predicted humans, but can help them narrow down where they should focus their research. Let's begin!
Subscribe or follow me on Twitter for more content like this!
The potential of AI in advancing scientific research
The ability of AI to predict promising experimental outcomes has significant implications for advancing scientific research. By identifying experiments with a higher likelihood of success, researchers can prioritize their efforts and resources more effectively. This could lead to faster progress in understanding complex systems, such as the brain, and potentially accelerate the development of new treatments for neurological disorders.
(BTW: If you're interested in learning more about how AI can accelerate health and scientific research, check out my article on how Google's LLM doctor is right more often than a real doctor, or my report on how DeepMind used AI to discover more than 2.2M new materials, representing 800 years worth of human research).
In the field of neuroscience, where experiments often involve multiple levels of analysis, from behavior to molecular mechanisms, and utilize a wide range of techniques, such as brain imaging, lesion studies, and pharmacological interventions, the assistance of AI in navigating this complexity could be particularly valuable. Neuroscience research often generates vast amounts of data from diverse sources, making it challenging for researchers to identify patterns and draw meaningful conclusions. LLMs, with their ability to process and integrate large volumes of information, could help researchers uncover hidden relationships and generate new hypotheses.
Moreover, the use of AI in predicting promising experiments could lead to a more efficient allocation of research funding. By prioritizing experiments with a higher likelihood of success, funding agencies and research institutions could ensure that resources are directed towards the most promising areas of investigation. This could potentially accelerate the pace of scientific discovery and lead to breakthroughs in our understanding of the brain and its disorders.
The BrainBench benchmark and model performance
To evaluate the predictive abilities of LLMs in neuroscience, the researchers created a benchmark called BrainBench. This benchmark consists of 200 test cases derived from recent Journal of Neuroscience abstracts, covering five neuroscience domains: Behavioral/Cognitive, Systems/Circuits, Neurobiology of Disease, Cellular/Molecular, and Developmental/Plasticity/Repair.
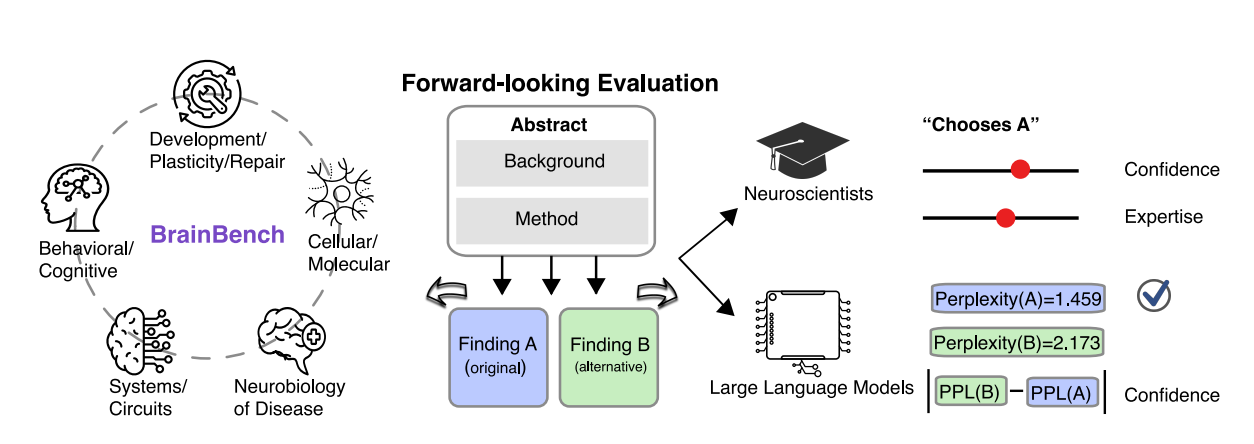
Each test case in BrainBench presents two versions of a neuroscience abstract: the original and an altered version with significantly changed results. LLMs and human experts were tasked with selecting the correct version of the abstract, and in doing so essentially predicting what the outcome of the experiment is likely to be:
We developed BrainBench to test LLMs’ ability to predict neuroscience findings (Fig. 2). LLMs have been trained extensively on the scientific literature, including neuroscience. BrainBench evaluates whether LLMs have seized on the fundamental patterning of methods and results that underlie the structure of neuroscience. Can LLMs outperform human experts on this forward-looking benchmark? In particular, BrainBench evaluates how well the test-taker can predict neuroscience results from methods by presenting two versions of an abstract from a recent journal article. The test-taker’s task is to predict the study’s outcome, choosing between the original and an altered version. The altered abstract significantly changes the study’s outcome (i.e., results) while maintaining overall coherence.
The results showed that LLMs outperformed human experts on BrainBench, with an average accuracy of 81.4% compared to 63.4% for human experts. This held true across all neuroscience subfields tested.
Remarkably, even smaller models with 7 billion parameters performed comparably to larger models, suggesting that the size of the model may not be the only factor in determining its predictive capabilities. This finding is particularly relevant for researchers who may not have access to the computational resources required to train and deploy larger models.
The researchers also found that fine-tuning the LLMs on neuroscience literature using Low-Rank Adaptation (LoRA) improved their performance. The fine-tuned model, called BrainGPT, achieved a 3% increase in accuracy on BrainBench compared to the base model. This highlights the importance of domain-specific training in enhancing the predictive abilities of LLMs. By exposing the models to a large corpus of neuroscience literature, the researchers were able to create a specialized model that outperformed the base model in identifying promising experiments.
Tell me more about LLMs
The LLMs used in this study are based on the transformer architecture and are trained on large amounts of text data, including scientific literature. During training, the model learns to predict the next token in a sequence based on the context provided by the preceding tokens. This allows the model to capture patterns and relationships within the data, enabling it to generate coherent and contextually relevant text.
The transformer architecture consists of multiple layers of self-attention mechanisms, which allow the model to weigh the importance of different parts of the input sequence when making predictions. This enables the model to capture long-range dependencies and learn complex relationships between words and phrases.
When presented with a test case from BrainBench, the LLM processes the text of the abstract and generates a probability distribution over the possible next tokens. By comparing the probabilities assigned to the original and altered versions of the abstract, the model can determine which version is more likely to be the correct one. The model's ability to integrate information from the entire abstract, including the background, methods, and results sections, allows it to make informed predictions about the likelihood of an experiment yielding positive findings.
The fine-tuning process using LoRA involves adding small, trainable layers to the base model, which adapt the model's weights to the specific domain of neuroscience. During fine-tuning, the model is exposed to a large corpus of neuroscience literature, allowing it to learn the patterns and conventions specific to this field. This domain-specific training enables the model to make more accurate predictions when presented with neuroscience abstracts, as demonstrated by the improved performance of BrainGPT on the BrainBench benchmark.
(LoRAs are also heavily used in image generation, see example here).
Implications, limitations, and future directions
This paper, I think, demonstrates the potential of LLMs in predicting promising neuroscience experiments. By outperforming human experts on the BrainBench benchmark, these AI models showcase their ability to identify research directions that are more likely to yield positive findings. This has big implications for the field of neuroscience and scientific research as a whole.
One of the main advantages of using AI to predict promising experiments is the potential to accelerate scientific discovery. By identifying experiments with a higher likelihood of success, researchers can focus their efforts on the most promising areas of investigation, potentially leading to faster breakthroughs in our understanding of the brain and its disorders. This could have far-reaching implications for the development of new treatments and therapies for neurological conditions (and could also create some weird incentives around picking experiments that an LLM is likely to believe will work in order to get more funding).
Another potential benefit of AI-assisted experiment selection is the reduction of research waste. By prioritizing experiments that are more likely to yield positive findings, researchers can minimize the time and resources spent on experiments that may not lead to meaningful results. This could lead to a more efficient use of research funding and help ensure that resources are directed towards the most impactful areas of investigation.
However, we should also note the limitations of the study. The research focused specifically on neuroscience and used a limited set of test cases. Further investigation is necessary to determine if these findings generalize to other scientific domains and larger datasets. Additionally, while AI can assist in identifying promising experiments, it cannot yet replace the critical thinking and creativity of human researchers. I think that for now, the role of AI should be seen as a complementary tool that can help guide and inform research decisions, rather than a replacement for human expertise.
Another potential limitation is the reliance on published abstracts as the basis for the BrainBench benchmark. While abstracts provide a concise summary of a study's background, methods, and results, they may not always capture the full complexity and nuance of the research. Future studies could explore the use of full-text articles or other sources of information to create more comprehensive benchmarks for evaluating the predictive abilities of LLMs.
As AI continues to develop, it will be essential for researchers to explore ways to effectively integrate these tools into their work while maintaining the critical thinking and creativity that drives scientific discovery. Future research should investigate the application of LLMs to other scientific fields and the development of more advanced models and fine-tuning techniques. This could involve exploring different architectures, training strategies, and domain-specific adaptations to further enhance the predictive capabilities of these models.
Another important direction for future research is the development of user-friendly interfaces and tools that allow researchers to easily access and utilize the predictive capabilities of LLMs. This could involve creating web-based platforms or software packages that enable researchers to input their experimental designs and receive feedback on the likelihood of success based on the predictions of fine-tuned models like BrainGPT.
Finally, it will be crucial to address the ethical implications of using AI in scientific research. As these tools become more prevalent, it will be important to establish guidelines and best practices to ensure that they are used responsibly and transparently. This could involve developing standards for data privacy, model interpretability, and the reporting of AI-assisted results in scientific publications.
Conclusion
The study by Luo et al. showcases the potential of large language models in predicting promising neuroscience experiments. By outperforming human experts on the BrainBench benchmark, these AI models demonstrate their ability to identify research directions that are more likely to yield positive findings. This has significant implications for the field of neuroscience and scientific research as a whole, as AI-assisted experiment selection could lead to faster breakthroughs, more efficient use of resources, and a reduction in research waste.
However, we still have to recognize the limitations of the study and the need for further investigation in other scientific domains. I think the development of more advanced models, fine-tuning techniques, and user-friendly tools will be essential to fully realize the potential of AI in scientific research.
As AI continues to advance, collaboration between researchers and AI experts will be a really powerful tool. By leveraging the strengths of both human creativity and AI's predictive capabilities, we can accelerate scientific discovery and tackle the most pressing challenges facing our world today. The study represents an important step in this direction, highlighting the exciting possibilities that lie ahead at the intersection of AI and scientific research. As the authors note, their "approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors."
Subscribe or follow me on Twitter for more content like this!


Comments ()