
The wisdom of the crowd: LLM prediction ability matches human crowds
AI systems now match or exceed human crowd accuracy at predictions.
In the ever-evolving field of artificial intelligence, language models have been making significant strides, achieving remarkable feats that were once thought to be exclusive to human cognition. For example, Anthropic's new Claude 3 language model seems to be aware when it's being tested or evaluated, adding an extra layer of complexity to the already impressive advancements in AI.
One new area where this progress is particularly noteworthy is in the realm of forecasting – the ability to make accurate predictions about future events.
In this blog post, we'll delve into a groundbreaking study that explores the forecasting abilities of large language models (LLMs) and compares them to the gold standard of human crowd forecasting. The study, conducted by researchers from the London School of Economics and Political Science, MIT, and the University of Pennsylvania, presents findings that challenge our understanding of AI capabilities and shed light on the potential of LLMs to rival human expertise in real-world scenarios.
Subscribe or follow me on Twitter for more content like this!
Context
Forecasting is the process of making predictions about future events based on past and present data, trends, and patterns. It plays a crucial role in economics, politics, technology, and science. Accurate forecasting enables better decision-making, resource allocation, and risk management.
Traditionally, the most reliable approach to forecasting has been the "wisdom of the crowd" effect, which leverages the collective intelligence of a diverse group of individuals. This phenomenon was famously demonstrated by Francis Galton in 1907, when he observed that the median guess of a crowd at a county fair accurately predicted the weight of an ox. Since then, numerous studies have confirmed that aggregating predictions from a large and diverse group of forecasters can lead to remarkably accurate results.
However, relying on human crowds for forecasting has several limitations:
- Cost and time: Assembling a sufficiently large and diverse group of skilled forecasters is expensive and time-consuming.
- Biases and correlations: Human judgments are subject to various cognitive biases, and correlations among individual predictions can undermine the crowd's collective accuracy.
- Scalability: Organizing and managing large-scale human forecasting tournaments is logistically complex and difficult to scale.
The Promise of AI Forecasting
In recent years, the rapid advancements in AI, particularly in the field of natural language processing, have raised the tantalizing possibility of using machine intelligence for forecasting. LLMs like GPT-3, GPT-4, and Claude 3 have demonstrated remarkable capabilities in understanding and generating human-like text (Claude 3 even knows its being tested now), leading researchers to investigate their potential for making accurate predictions about future events.
(Related reading: LLMs surpass humans in predicting which neuroscience experiments will succeed (81% vs 64%))
However, previous studies have shown that individual LLMs often underperform compared to human crowd forecasts. For example, Schoenegger and Park (2023) found that GPT-4, despite its impressive language skills, failed to outperform a simple no-information benchmark of predicting 50% probability for all binary questions.
The Wisdom of the Silicon Crowd
In this new paper, though, Schoenegger et al. (2024) hypothesized that the key to unlocking LLMs' forecasting potential might lie in aggregating predictions from multiple diverse models – a machine analog of the "wisdom of the crowd" effect. To test this idea, they conducted two studies:
Study 1: LLM Ensemble vs. Human Crowd
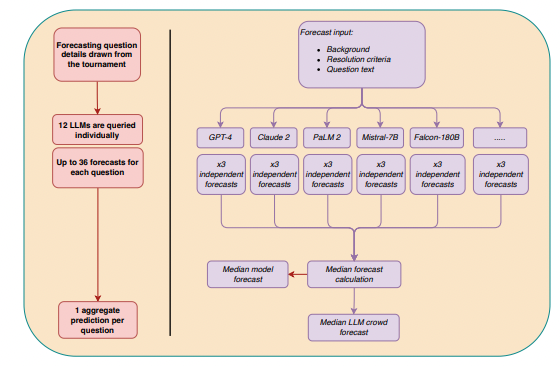
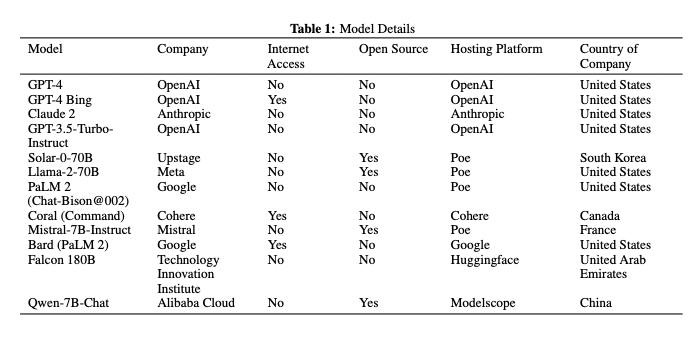
In the first study, the researchers collected predictions from 12 diverse LLMs on up to 31 binary questions drawn from a real-time forecasting tournament on Metaculus, where 925 human forecasters also participated over a 3-month period. The LLMs spanned a wide range of architectures, training datasets, and fine-tuning approaches, including models from OpenAI, Anthropic, Google, Meta, and others.
For each question, the researchers queried each LLM three times using a standardized prompt that included the question background, resolution criteria, and instructions to respond as a "superforecaster." They then computed the median prediction across all non-missing forecasts from the 12 LLMs to obtain the "LLM crowd" forecast.
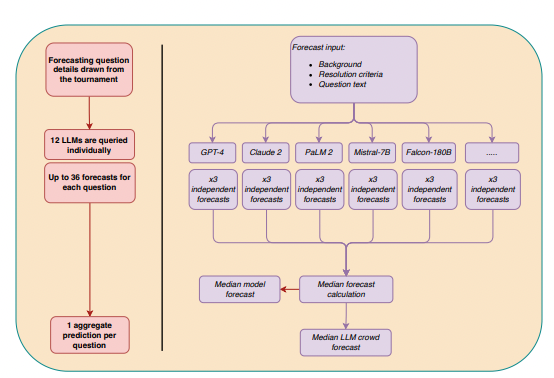
The results were striking: The LLM crowd significantly outperformed a no-information benchmark of predicting 50% on all questions (p = 0.026) and was statistically indistinguishable from the human crowd's accuracy (p = 0.850). An exploratory equivalence test further suggested that the LLM and human crowds were equivalent within medium effect size bounds.
Study 2: Improving LLM Forecasts with Human Cognitive Output

The second study investigated whether LLMs' forecasting accuracy could be further improved by providing them with the human crowd's median prediction as additional information. The researchers focused on two state-of-the-art models, GPT-4 and Claude 2, and employed a within-model design where each model made an initial forecast and then an updated forecast after being exposed to the human median.
Both models showed significant improvements in accuracy after receiving the human crowd information, with GPT-4's average Brier score (a measure of forecast error) decreasing from 0.17 to 0.14 (p = 0.003) and Claude 2's from 0.22 to 0.15 (p < 0.001). The models also appropriately narrowed their prediction intervals when the human median fell within their initial range, demonstrating an ability to incorporate the additional information in a rational manner.
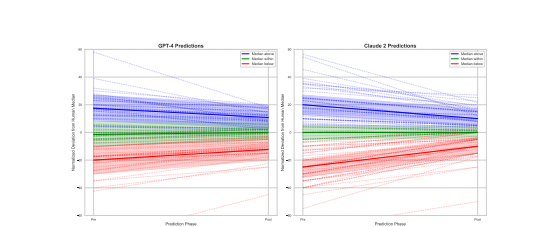
However, an exploratory analysis revealed that simply averaging the initial machine forecast with the human median yielded even better accuracy than the models' updated predictions. This suggests that while LLMs can benefit from human cognitive output, their reasoning capabilities may not yet be optimally calibrated for integrating such information.
Implications and Limitations
The findings here have significant implications for the future of forecasting and AI-human collaboration:
- Scalable and cost-effective forecasting: By harnessing the "wisdom of the silicon crowd," organizations can obtain high-quality forecasts faster and more cheaply than relying on human crowds alone. This could make data-driven decision-making more accessible across various domains.
- Complementary strengths of humans and AI: While LLM ensembles can rival human crowd accuracy, the study also shows that human cognitive output can further improve machine forecasts. This highlights the potential for synergistic collaboration between human experts and AI systems in forecasting tasks (and is somewhat contradictory to this study that found that AI outperforms human doctors regardless of their level of involvement at diagnosing difficult diseases).
- Advancing AI reasoning capabilities: The study provides evidence of LLMs' ability to engage in sophisticated reasoning (or at least what appears to be reasoning) and information integration, albeit with room for further optimization. As models continue to improve, we may see even greater strides in their forecasting performance.
However, it's crucial to acknowledge the limitations and caveats of the research:
- The study focused on short-term (3-month) binary forecasts. More work is needed to assess LLM performance on longer-term predictions and more complex question types.
- The LLMs exhibited an acquiescence bias, tending to predict probabilities > 50% even when the empirical base rate was close to even. They also showed poor calibration overall, indicating a need for further refinement.
- As LLMs' training data becomes increasingly outdated, their forecasting accuracy may degrade without regular updates to keep pace with changing real-world conditions.
Conclusion
Despite these limitations, this study represents a significant milestone in demonstrating the potential for AI systems to match and even exceed human collective intelligence in certain forecasting domains. By leveraging the "wisdom of the silicon crowd," we can make high-quality, data-driven predictions more scalable and accessible than ever before.
Of course, LLMs are not a total replacement for human judgment, and there will always be a vital role for human experts in interpreting, contextualizing, and acting on machine forecasts. But as AI capabilities continue to advance, it's becoming increasingly clear that the future of forecasting will be one of close collaboration and synergy between human and machine intelligence.
The era of the silicon crowd is upon us – and that's an exciting prospect indeed for anyone who values accurate, timely, and actionable predictions about the complex world we inhabit. As researchers continue to push the boundaries of what's possible with AI forecasting, I'll be sure to keep an eye on this for you.
Subscribe or follow me on Twitter for more content like this!


Comments ()