
AI can discover hidden relationships in tabular data
Identifying new classes within unlabeled data sets
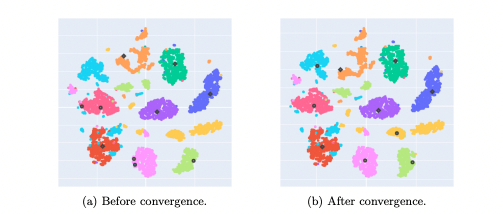
Machine learning systems are evolving to mimic a fundamental human ability: the recognition and categorization of new, unseen entities. This skill, crucial in the dynamic world of data, forms the basis of what's known in machine learning as Novel Class Discovery (NCD). NCD challenges AI models to identify and learn new data classes in an unsupervised manner, a task that's becoming increasingly vital as the volume and variety of data grow.
A recent paper offers a fresh perspective on this challenge, focusing on the use of labeled data from known classes to cluster unlabeled data into novel categories. The central thesis of this research is that insights gleaned from known classes can be pivotal in uncovering and understanding new ones. This approach is not just about mapping the unknown into predefined categories; it's about expanding the boundaries of what the model "understands" as a category.
In the following sections, we'll dive deeper into the methodologies proposed in this paper. We'll explore how the researchers leveraged existing data to break new ground in NCD, the implications of their findings, and how this might influence future directions in machine learning research. This exploration is not just a technical deep dive; it's a journey into how machine learning can continue to evolve, mirroring human learning processes in an ever-changing world. Let's go!
Subscribe or follow me on Twitter for more content like this!
The Broader Context
Most of today's powerful deep learning models are trained on fully labeled datasets where all the possible classes are known in advance (such as ImageNet for images). However, this closed-world assumption does not hold true in many real-world applications. For example, a model trained to detect common objects could be deployed in a new geographical area and encounter objects it has never seen before. Or a recommender system could start seeing new types of products. In these scenarios, the model needs to be able to adapt and extend its knowledge to these novel classes in an unsupervised way, without any labeled examples.
This capability would allow machine learning systems to incrementally acquire new knowledge over time in a lifelong learning fashion, rather than requiring full retraining on massive labeled datasets. It moves towards more open-world and human-like learning. Enabling models to discover and incorporate new concepts without supervision remains an open research challenge.
Limitations of Prior Approaches
A number of recent studies have tackled this novel class discovery problem. However, most existing methods make unrealistic assumptions - they presume the number of novel classes is known in advance, or even use the unlabeled novel class labels when tuning model hyperparameters. These techniques have achieved some success on image data, by leveraging advanced practices like data augmentation.
However, these assumptions preclude application to real-world settings. Plus, many techniques developed for computer vision do not transfer well to other data modalities like tabular data. Simpler models with fewer hyperparameters tend to generalize better on tabular data.
So the authors of this new study aimed to develop an NCD approach without unrealistic prerequisites, with a focus on tabular data scenarios.
The Proposed Techniques
The research team tackled the challenge of Novel Class Discovery (NCD) in tabular data by crafting three innovative methods, each uniquely utilizing the knowledge from known classes. Their approach was methodical and precise, aimed at enhancing the accuracy and efficiency of class discovery in datasets where some classes are labeled (known) and others are not (novel).
First up was the NCD k-means method, an intelligent twist on the classic k-means++ algorithm. The team's strategy began by setting initial centroids based on the mean class points of the known classes, leveraging the ground-truth labels. This setup provided a solid starting point for the algorithm. For the novel classes, the team adopted a strategy of selecting new centroids from the unlabeled set, with the selection probability smartly decreasing for points closer to existing centroids. This approach was refined by repeating the initialization process multiple times, each time retaining the centroids that led to the most cohesive clusters.
The second method, NCD Spectral Clustering, ventured into graph theory territory. The team constructed an adjacency matrix using a Gaussian kernel, a step crucial for capturing the relationships between data points. A key part of this method was the optimization of the kernel's temperature parameter, �σ, for which they employed a minimum spanning tree approach to ensure a well-connected graph. The process involved forming a spectral embedding from the eigenvectors of the normalized Laplacian and then partitioning these points using k-means. The brilliance of this method lay in its ability to use the performance on known classes as a guide to find parameters that would suitably represent the novel classes.
The third and final method, Projection-Based NCD (PBN), was a comprehensive approach involving an encoder, a classification network, and a decoder. The encoder and decoder were designed to learn and reconstruct a shared representation of both known and novel classes. The classification network, trained to identify the known classes, played a crucial role in integrating their features into the shared representation. The training process was a careful balancing act, using a loss function that combined aspects of both classification accuracy and reconstruction fidelity.
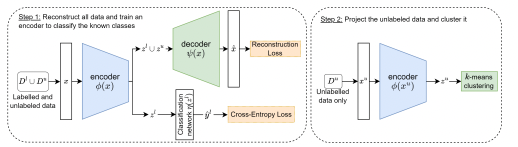
A pivotal aspect of the team's approach was hyperparameter optimization, handled through a k-fold cross-validation technique. Here, they cleverly treated a subset of known classes as 'hidden', training the model on this modified data split and evaluating it based on the performance on these hidden classes. This strategy enabled them to fine-tune the model without relying on the labels of the novel classes.
Estimating the number of novel classes was another challenge they adeptly addressed. They applied Cluster Validity Indices (CVIs) within the latent space defined by PBN, capitalizing on the shared features between known and novel classes to make accurate estimates.
Bringing all these components together, the research team embarked on a rigorous procedure involving training, estimation, and evaluation over various data splits and hyperparameter combinations. The culmination of this process was the selection of the best-performing parameter set, ready to be deployed for the final evaluation of the model's effectiveness in discovering novel classes. This holistic approach showcased not only their technical acumen but also a deep understanding of the intricacies involved in Novel Class Discovery in tabular datasets.
Overview of the Results
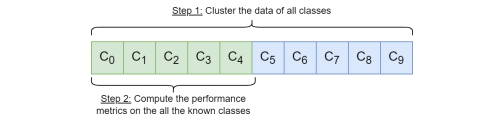
The researcher begin by comparing enhanced clustering methods, NCD k-means and NCD Spectral Clustering, with their standard counterparts. This comparison is crucial when the number of new groups in the dataset is known beforehand. Their results show that the enhanced methods generally outperform the standard ones, indicating their effectiveness in scenarios with known group quantities.
Performance Across Different Scenarios
A critical aspect of the study is evaluating how these methods perform across various datasets. Interestingly, no single method consistently emerged as the best across all tests. However, NCD Spectral Clustering frequently achieved high accuracy, making it a particularly effective method in diverse situations.
Effectiveness of the Partition-Based Network (PBN)
The PBN was tested against both a basic approach and the more complex TabularNCD. PBN consistently outperformed these methods, especially in cases where the data groups varied greatly. This indicates its strong potential for practical applications.
Challenges of Complexity and Overfitting
TabularNCD's complexity, due to its many adjustable settings (hyperparameters), led to a common problem in machine learning called overfitting. This issue occurs when a model becomes too tailored to the training data, diminishing its ability to perform well with new or different data.
Adaptability in Uncertain Scenarios
The study further examines how these methods perform when the number of new groups is unknown - a common real-world challenge. PBN maintained its effectiveness in these scenarios, demonstrating its adaptability and practical value. In contrast, the basic method and NCD Spectral Clustering struggled more in these uncertain conditions.
Overall Implications
The study concludes by underscoring the effectiveness of the PBN approach for novel class discovery in datasets. With its balanced approach and fewer hyperparameters, PBN avoids the pitfall of overfitting, making it a versatile and practical tool for various data analysis and machine learning applications.
Conclusion
This research offers a logical progression through the complexities of novel class discovery in tabular data, highlighting the strengths and limitations of different methods and emphasizing the practicality and effectiveness of the PBN method.
This work shows that novel class discovery is viable on tabular data without relying on unrealistic access to novel class information during training. While limitations exist, it represents promising progress on an important open problem.
Potential applications include identifying new categories of census data, insurance claims, or customer segments over time. The techniques could be extended to time series or graph data as well.
At a high level, this research demonstrates the feasibility of adaptable machine learning systems that can discover and incorporate new knowledge in the absence of labels. With further research, AI may start to learn concepts in a more open-ended, lifelong manner - getting us closer to flexible and general artificial intelligence! Until then, I'll watch this space closely!
Subscribe or follow me on Twitter for more content like this!


Comments ()